Are you struggling to compare similarities or differences between two files from the Linux command line? Then don't worry; in this article, we will guide you on how to perform those tasks without any external tools, just by using the built-in commands.
Before continuing, check the following two files that we will use as samples to demonstrate all the command examples that will be discussed in this article:
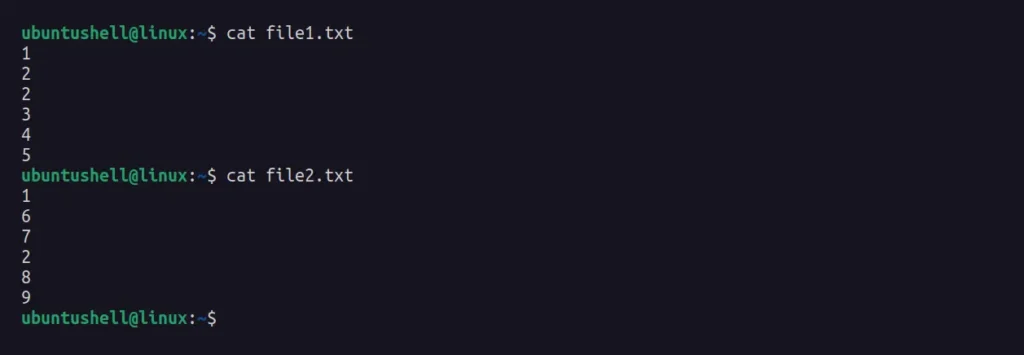
As you can clearly see, '1' and '2' are repeated in both files, but surprisingly, '2' is declared multiple times in the first file, and '3', '4', '5', '6', '7', '8', '9' are the differences between the two files.
So, let's see how one can find the similarities and differences between these two files from the Linux terminal.
Find the Common String Between Two Files
The first thing we do is find the common string between both files, and for that, you can use multiple Linux commands. For the sake of this article, I'll focus on two Linux commands: awk and grep.
So, to find a similar string between both files that is not repeated, you can use the following awk command:
$ awk 'NR==FNR{a[$1]++;next} a[$1] ' file1.txt file2.txtOutput:

You can see that it has easily printed the common '1' and '2' strings between both files. To understand which options we used along with the command, check out the list below.
NR==FNR{a[$1]++;next: It will compare the two files by breaking each string as the key in the associative array, then incrementing the value to the next line.a[$1]: This is used to process the second file, so if the first field (in the first file) of the current line exists in a second file, then awk prints the line.
To compare a common string between two files using grep, you can use the following command:
$ grep -o -w -F -f file1.txt file2.txt | sort | uniq -cOutput:

Whereas,
-o: It will ensure printing only the matching parts of the line rather than the entire line.-w: It ensures matching whole words only, rather than matching substrings within longer words.-F: It ensures treating patterns as fixed strings rather than regular expressions, which is useful when searching for literal strings.-f file1.txt file.2.txt: These are the files that will be used to search for patterns.sort: This command is used for sorting lines of text alphabetically.uniq -C: This command is used to remove duplicate lines from a sorted file and to count the number of occurrences of each unique line.
Find the Difference Between Two Files
Finding the difference between two files is a different task than comparing the similarities. For example, in both files, the string '2' is common, but in the first file, it's repeated twice, and in the second file, it's repeated once, so what do you think the extra two will consider as similarities or differences between those two files?
Let's find out by using the diff command to check which strings exist in the first file but do not exist in the second file.
$ diff file1.txt file2.txt | grep '<' | cut -c 3Output:

As expected, the extra '2' is considered the difference between those two files. Therefore, when comparing two files, the number of single string repetitions should match between them.
Let's find out which strings exist in the second file but do not exist in the first file using the comm command:
$ comm -13 <(sort file1.txt) <(sort file2.txt)Output:

This time, if you notice, the '2' did not appear in the output; instead, we got '6', '7', '8', and '9', which do not exist in the first file. The reason for '2' not appearing is that it's repeated only once in the second file. Hence, while comparing the files, they're considered to have similarities rather than differences.
Finally, let's find out all the different strings repeated in both files at once using the following command:
$ comm -3 <(sort file1.txt) <(sort file2.txt) | tr -d '\t'Output:
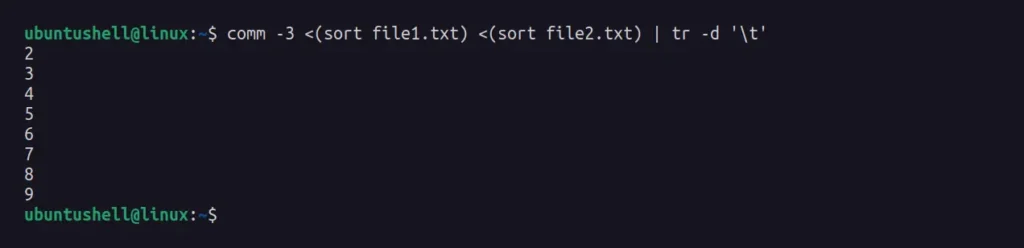
As you can see, we got the difference between first and second files at once that do not exist in each other's files, including that extra '2' that repeated twice in the first file.
Find Similarities and Differences Between Two Files Using Vim
There are many GUI tools that can help you find similarities or differences between two files easily, without needing to remember long commands that we discussed previously.
Now, instead of those GUI tools, I prefer using the Vim editor, which comes with features allowing you to quickly find similarities and differences between two files in a colorful format.
$ vimdiff file1.txt file2.txt
#OR
$ vim -d file1.txt file2.txtOutput:
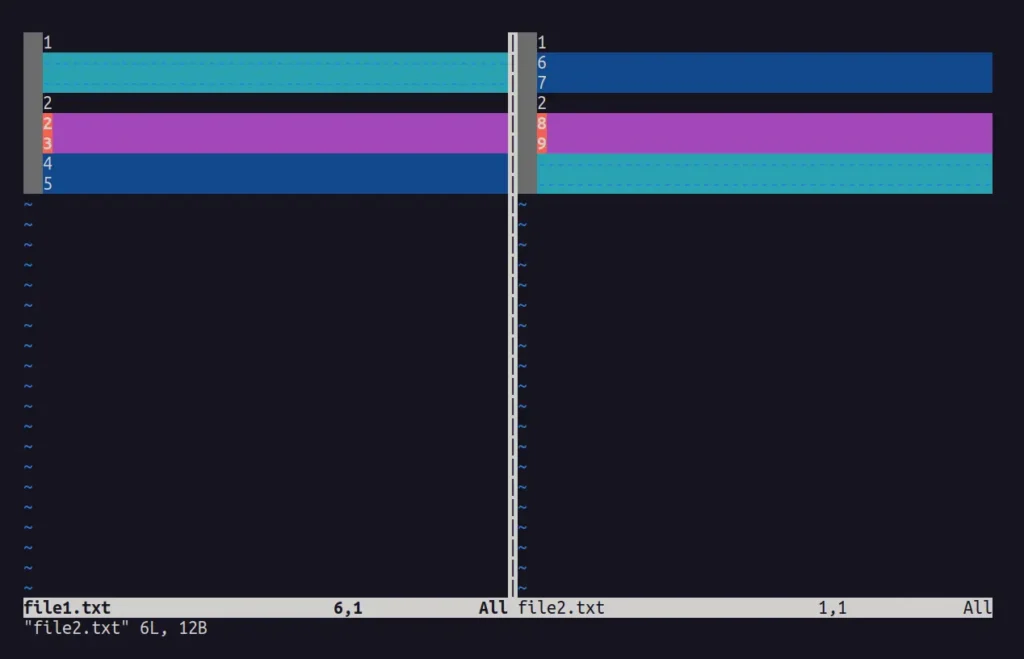
The repeated strings are placed corresponding to each other, while differences are either placed in empty spaces or highlighted with a red mark.
That's it; this article ends here. I hope you learned something new today. Do let me know what the next topic should be in the comment section.


